
Teaching a machine to read, how LLM's comprehend text
Understanding what embeddings are, how they work, and why they are important to you.

In my earlier blog posts about how Python code translates into CPU instructions ((can be read here: part 1, part 2), we explored the fundamental concept that computers don’t understand human ideas like text or language. Instead, everything is broken down and transformed into machine-readable instructions. In this post, we’ll delve into how large language models (LLMs) like ChatGPT and Claude process your text-based questions and turn them into something they can interpret and respond to.
Why Does This Matter?
You might ask, “Why do I need to know this?” After all, most people simply interact with LLMs via a chat interface, and that works just fine. This knowledge might not make you a better prompt engineer, but it will give you insight into how we, as data engineers, can engage with unstructured data in entirely new ways.
Traditionally, working with text meant parsing it, extracting relevant details, and storing them in structured formats like rows and columns. Searching for information required keyword-based queries. This made working with large amounts of unstructured data either less useful or prohibitively expensive to process. Now, thanks to advancements in text comprehension driven by LLMs, we can directly leverage these models for tasks that were once complex and manual. While this post focuses on text, these techniques are also applicable to other data types like images and audio.
Neural Networks
Let’s first start with a superficial introduction to LLM. LLM are neural networks, and although the type of network, has changed over time (currently the transformer architecture is all the rage), the underlying principles we will go through, remain the same.
Neural networks start with an input layer, which feeds in to one or more hidden layers, which in the end returns an output layer. Each layer is a just a vector (list) of numbers.

If we look illustration above it has one input layer, two hidden layers and 1 output layer.
Suppose we feed the input layer two numbers i1 = 5 and i2 = 3.
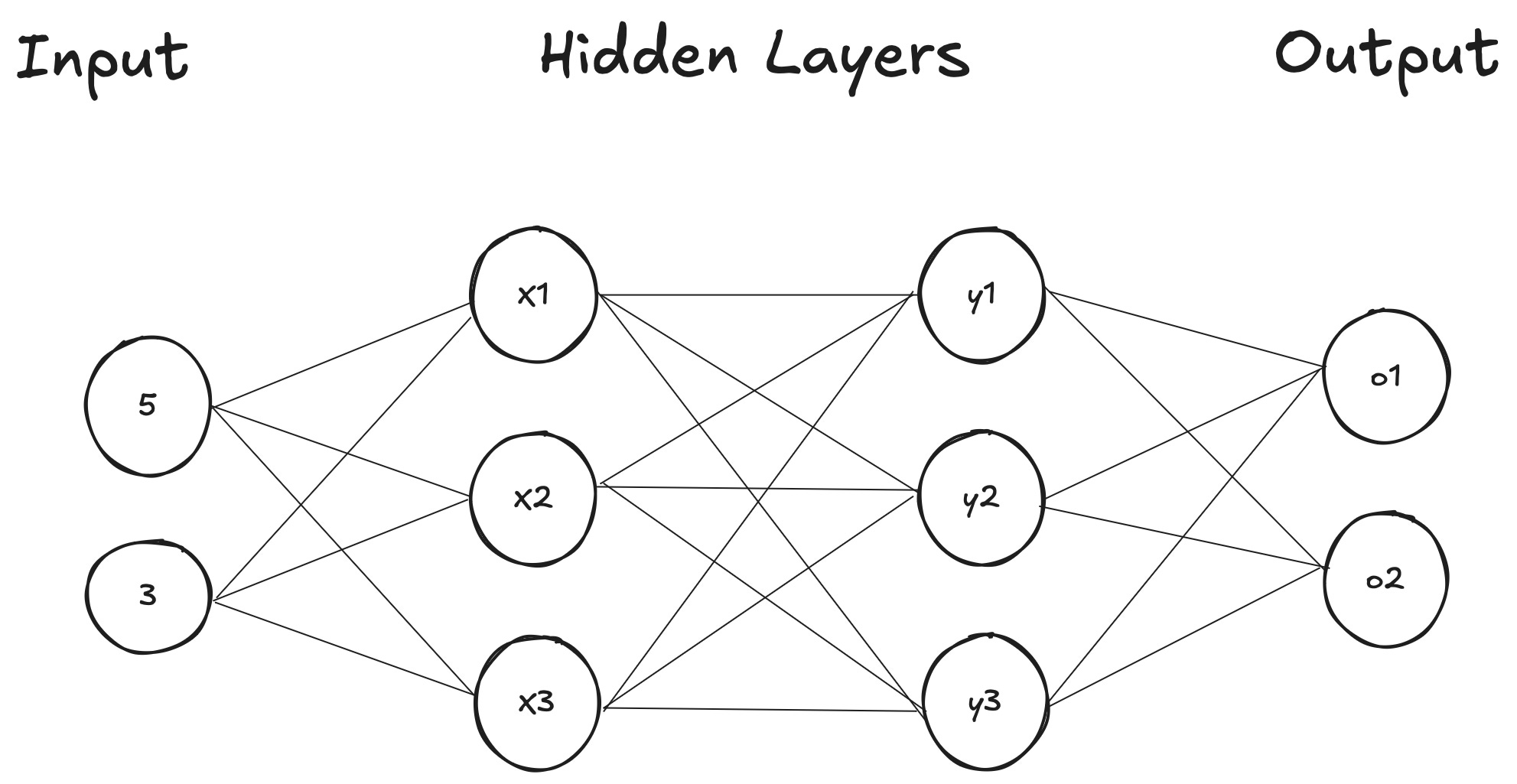
To populate the next layers we do a calculation for each node in our network (we call these neurons). That could look like this:
x1 = i1 + i2 = 8
x2 = (i1 + i2) / 2 = 4
x3 = i1 - i2 = 2
These transformations continue layer by layer until the output layer generates a final output vector. The process of determining the calculation steps between each layer is known as training the model. While this is a fascinating and complex topic, it’s beyond the scope of this blog post. What matters for now is understanding that for an LLM to produce a result, it requires an input vector—a list of numbers that represents the data.
In this post, we’ll focus on the journey from a human-readable question to a model-readable input vector.
Embeddings
As you may have guessed from the subtitle, the input vector is called an embedding. An embedding is essentially a list of numbers that represents something about the text. When we interact with an LLM, we are communicating through an interface that converts our text-based question into an embedding, which is then sent to the model for processing.
An embedding can represent almost anything we choose. For example, we could create an embedding to indicate whether a given piece of text contains the word "Hello." This could be represented as a simple vector, where 1 means the text includes the word "Hello," and 0 means it does not. The process might look something like this:
"Hello World" => EMBEDDING MODEL => [1]
"Hi World" => EMBEDDING MODEL => [0]Bag-of-words
However it will be difficult to use this embedding in any meaningful way. A more structured approach is to create a model that looks for predefined words and counts how many times each word appears in the text. This approach is known as Bag-of-Words.
Let’s say we want to determine whether a given text is about farm animals. We could look for specific words like Horse, Sheep, Pig, Cow, and Chicken. Using the Bag-of-Words method, the model might process text like this:
"The farm has a lot of horses, pigs, and cows, however, there are no sheep." => [1, 1, 1, 1, 0]
"There are a lot of cars in the city." => [0, 0, 0, 0, 0]In this example, the higher the sum of the vector, the stronger the relationship to farm animals. While useful for basic classification, this technique has significant limitations when it comes to understanding the meaning of text. Consider these two sentences:
"The farm has a lot of horses, but no cows."
"The farm has a lot of cows, but no horses."
Using Bag-of-Words, both sentences would generate the same embedding because the method ignores the order and context of the words. However, the meanings are clearly different. For instance, the sequence a lot of horses conveys something entirely different from no horses, but Bag-of-Words does not account for this distinction. By removing word order, we lose critical contextual information, making the method inadequate for more complex text analysis.
Sentence Vectorisation
To make embeddings truly meaningful, we need to go beyond simply counting words. Instead, we must understand the context in which words appear. A step forward is to create a list of all unique words in a text and map them to numeric values. Let’s explore this with an example.
Consider the sentence:
"The man and the woman has a horse but not a cow, the horse is cute."
This sentence contains the following unique words:
the, man, and, woman, has, a, horse, but, not, cow, is, cute
We can assign each unique word a numeric value:
"the" => 1
"man" => 2
"and" => 3
"woman" => 4
"has" => 5
"a" => 6
"horse" => 7
"but" => 8
"not" => 9
"cow" => 10
"is" => 11
"cute" => 12Using this mapping, the sentence can be converted into the following embedding:
[1, 2, 3, 1, 4, 5, 6, 7, 8, 9, 6, 10, 1, 7, 11, 12]By preserving the order of words, this embedding captures some context that was lost in earlier approaches like Bag-of-Words. The order of words matters, and this method reflects that. However, it still treats each word as an independent entity, which limits its ability to capture higher-level meanings.
Why Word Order Alone Isn’t Enough
For a human reader, it’s easy to see that the sentence:
I love playing with my dog.
...is semantically similar to:
Spending time with my dog is very enjoyable.
However, using the numeric mapping above, these sentences would result in very different embeddings, even though their meanings are closely related.
Worse still, a sentence like:
You love playing with my feelings.
...would produce an embedding that appears numerically closer to the first sentence, despite its completely different meaning. This happens because the approach treats words individually and doesn’t consider the relationships or similarities between words.
Contextual Embeddings
To capture the context of words in a sentence, we can adopt a more sophisticated embedding approach, such as Word2Vec. Word2Vec isn’t a single technique but a family of models designed to embed words based on their context. It works by modeling the probability of a word appearing in a given context. For example, the word "horse" is far more likely to follow the phrase "The farmer has a" than "The farmer has a quantum computer." As a result, Word2Vec would embed the word farmer closer to horse than to quantum computer.
Unlike earlier methods that represented each word as a single value, Word2Vec represents each word as a vector with multiple attributes, capturing its relationships and context.
Let’s consider three words: Horse, Farmer, and Doctor.
The words horse and farmer frequently appear together in texts about farming.
The words farmer and doctor may co-occur in texts about professions, but horse and doctor rarely share context.
Word2Vec assigns each word a vector based on its probability of co-occurrence with related words. This could look like:

Here, each number represents the word’s "belongingness" to a particular category, with scores ranging from 0 (weak association) to 1 (strong association). Using these contextual embeddings, we can model the real-world meaning of words instead of treating them as isolated entities.
Why Context Matters in Embeddings
Using this approach, words like Horse and Pony—which share similar contexts—would be placed close together in the vector space. In contrast, earlier techniques would treat them as entirely separate entities.
Now, let’s revisit the example sentences:
"I love playing with my dog and spending time with my pet."
"You love playing with my feelings."
Word2Vec would likely produce similar embeddings for the first sentence and a related one like "Spending time with my dog is enjoyable." However, the second sentence, despite sharing some common words, would be less similar because it diverges in context and meaning. This is because Word2Vec takes into account the relationships between words rather than simply looking at their individual occurrences.
Moving Beyond Words: Sentence and Paragraph Embeddings
While Word2Vec improves upon individual word embeddings, it still processes words in isolation. To fully capture meaning, we need embeddings for entire sentences or paragraphs. By grouping text into unique sentences or paragraphs and using them as input for embedding models, we can preserve higher-level context.
Techniques like Bert or Sentence Transformers enable this. They go beyond individual word relationships to capture the meaning of entire sections, making them invaluable for tasks like document classification and semantic search.
Conclusion
By shifting from simple word counts to contextual embeddings, approaches like Word2Vec enable us to capture relationships between words and their contexts. While individual word embeddings are a significant improvement, grouping words into sentence or paragraph embeddings unlocks even greater potential. These advanced techniques allow models to interpret text in ways that align more closely with human understanding.
But this isn’t just valuable for building LLMs—it’s a powerful tool for data engineers too. Consider a scenario where you have a large database of contracts, each written in a unique style. If you wanted to group these contracts by payment terms, the traditional approach would involve manually extracting this information or relying on a set of rigid and often unreliable rules.
Now, with a bit of clever engineering and modern text embedding techniques, you can analyse this unstructured data more effectively. For example, embeddings allow you to query your data using natural language: “Show me all contracts with net 30 payment terms.” The model can interpret your query, retrieve relevant results, and even adapt to different linguistic styles.
This capability significantly lowers the barrier for organizations to create meaningful, user-friendly data products. Instead of wrestling with data formatting and parsing, teams can focus on deriving insights and building tools that drive decision-making.